代码中的 Zipf 定律
统计语言学中有一个 Zipf 定律,讲的是在自然语言的语料库里,一个单词出现的频率与它在频率表里的排名成反比。
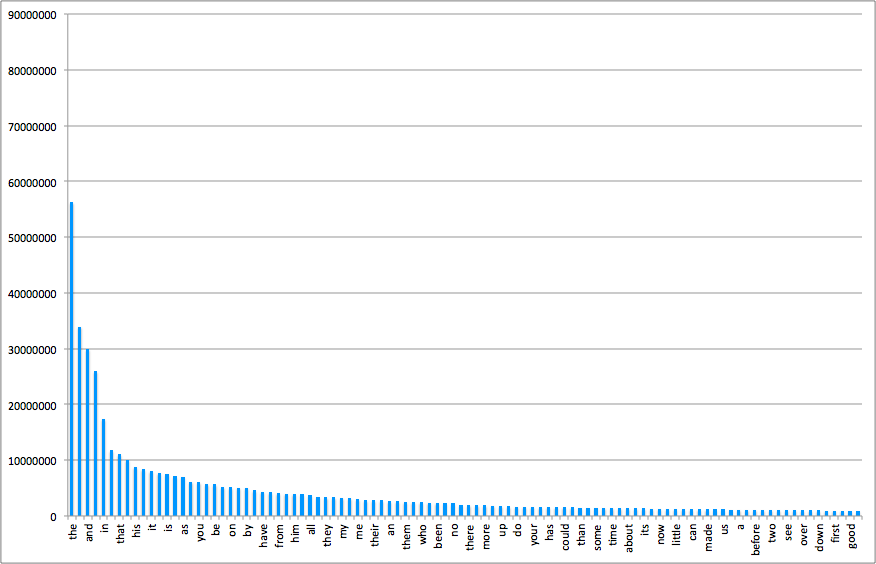
根据 Wikitionary 上的一份资料,英文中出现频率最高的 10 个单词是这样的:
排名 词 计数
1 the 56271872
2 of 33950064
3 and 29944184
4 to 25956096
5 in 17420636
6 I 11764797
7 that 11073318
8 was 10078245
9 his 8799755
10 he 8397205
如果把英文中出现频率最高的 100 个单词按出现频率以及排名画成直方图,可以得到下面的图像:
我们的确可以用一条曲线来拟合这个排名数据,如下:
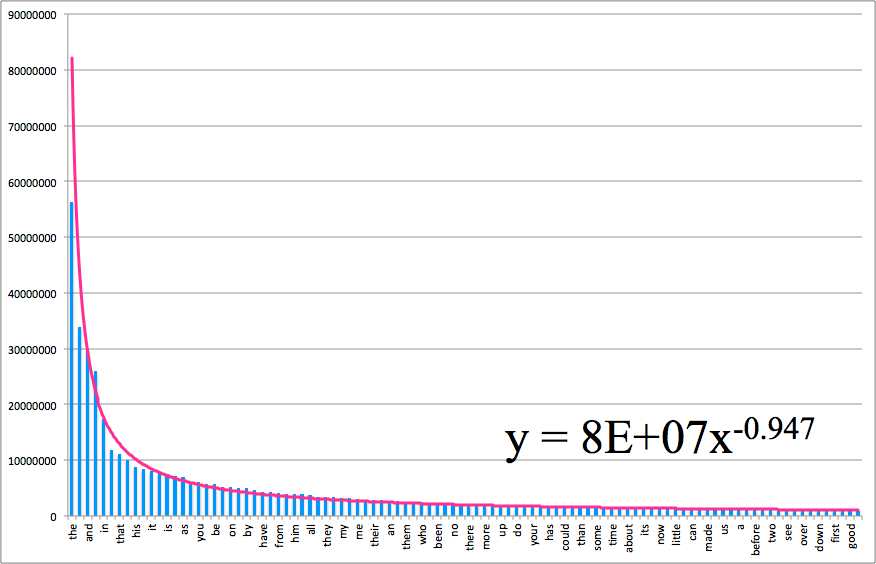
这条曲线的方程是 \(y = ax^b\) 的形式,也就是一个幂函数曲线。
事实上,Zipf 定律中的“反比”即是 \(y = \frac{a}{x}\),也即上面 \(b = -1\) 时的情况。也即 Zipf 定律其实也是一种幂律。
这是一个实验定律,而非理论定律,但是的确在很多现象中可以被观察到。比如不仅是自然语言,我们平常写的代码中也存在这个定律,就像淘宝的前端框架 KISSY 中。
我们来写一个 Python 脚本,统计一下 KISSY 所有 js 文件中的词频。代码如下:
# -*- coding: utf-8 -*-
#
# author: oldj
# blog: https://oldj.net
# email: oldj.wu@gmail.com
#
u"""Count word frequency in codes.
Usage:
python cf.py --folder=folder_path --ext=filename_extension
Example:
python cf.py --folder=/Users/wu/ozcode/kissy/src --ext=js
"""
import os
import sys
import re
ROOT = "/Users/wu/ozcode/kissy/src"
#ROOT = "/Users/wu/studio/tb-assets"
def getWords(content):
return re.findall(r"w+", content)
def dealFile(path, words):
c = open(path).read()
fwords = getWords(c)
for w in fwords:
if w not in words:
words[w] = 0
words[w] += 1
def walk(root_path, ext):
words = {}
count = 0
for root, dirs, files in os.walk(root_path):
for fn in files:
if fn.lower().endswith(ext):
count += 1
print("%d. %s" % (count, fn))
dealFile(os.path.join(root, fn), words)
save(ext, words)
return count
def save(ext, words):
kws = words.items()
kws.sort(key=lambda a: -a[1])
fn = "s_%s.txt" % ext
f = open(fn, "w")
for k, v in kws:
ln = "%st%d" % (k, v)
# print(ln)
f.write("%sn" % ln)
f.close()
print("-" * 50)
print("output -> %s" % os.path.abspath(fn))
def main(folder, ext):
counts = []
c = walk(root_path=folder, ext=ext)
counts.append(c)
if __name__ == "__main__":
folder = None
ext = None
argvs = sys.argv[1:]
for kv in argvs:
k, _, v = kv.partition("=")
if k == "--folder":
folder = v
elif k == "--ext":
ext = v
if folder and ext:
main(folder, ext)
else:
print(__doc__.replace("cf.py", __file__))
使用方法为:
python cf.py --folder=folder_path --ext=filename_extension
当然,要将上面的 folder_path 和 filename_extension 替换为你真实的内容,比如:
python cf.py --folder=/Users/wu/ozcode/kissy/src --ext=js
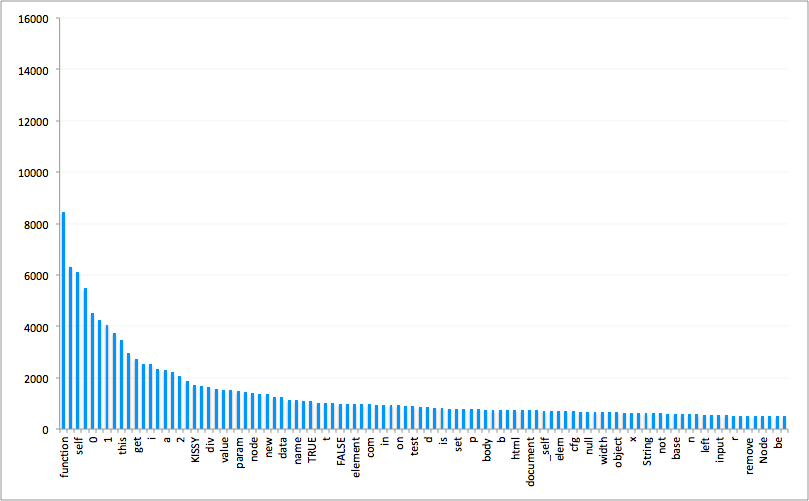
统计 KISSY 源码的 src 目录下的所有 .js 文件,找出所有匹配正则 \w+ 的词,并按照词频从大到小排列,可以得到一个列表,其中前 10 项是这样的:
排名 词 出现次数
1 function 8437
2 var 6312
3 self 6120
4 if 5473
5 0 4525
6 return 4242
7 1 4057
8 S 3751
9 this 3452
10 expect 2947
当然,KISSY 的开发者非常勤奋,更新很快,你最后得到的词频和我上面的可能会有一些不同,但比例应该是大致一致的。把前 100 项画成直方图,看起来是这样的:
这些数字也与一条幂函数曲线吻合得非常好:
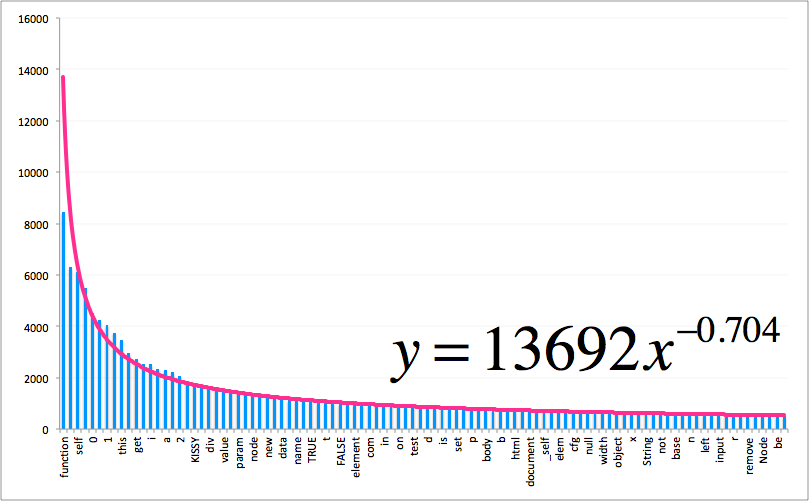
除了 js,KISSY 中所有 CSS 文件的词频也符合同样的分布。我甚至还统计了一下工作环境下 SVN 上的所有 js/css 文件(这些文件出自数百名工程师之手)中的词频,发现这个规律仍然是存在的。
评论:
Python中有 from numpy.random import zipf 可以处理这种分布的数据... 貌似, 不记得了. 呵呵
你厉害,原来这个库里有啊!
囧... 因为以前写某篇论文时, 用这个忽悠了下...