关于 JavaScript 的数组随机排序
JavaScript 开发中有时会遇到要将一个数组随机排序(shuffle)的需求,一个常见的写法是这样:
function shuffle(arr) {
arr.sort(function () {
return Math.random() - 0.5;
});
}
或者使用更简洁的 ES6 的写法:
function shuffle(arr) {
arr.sort(() => Math.random() - 0.5);
}
我也曾经经常使用这种写法,不久前才意识到,这种写法是有问题的,它并不能真正地随机打乱数组。
问题
看下面的代码,我们生成一个长度为 10 的数组 ['a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j'],使用上面的方法将数组乱序,执行多次后,会发现每个元素仍然有很大机率在它原来的位置附近出现。
let n = 10000;
let count = (new Array(10)).fill(0);
for (let i = 0; i < n; i ++) {
let arr = ['a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j'];
arr.sort(() => Math.random() - 0.5);
count[arr.indexOf('a')]++;
}
console.log(count);
在 Node.JS 6 中执行,输出 [ 2891, 2928, 1927, 1125, 579, 270, 151, 76, 34, 19 ](带有一定随机性,每次结果都不同,但大致分布应该一致),即进行 10000 次排序后,字母 'a'(数组中的第一个元素)有约 2891 次出现在第一个位置、2928 次出现在第二个位置,与之对应的只有 19 次出现在最后一个位置。如果把这个分布绘制成图像,会是下面这样:
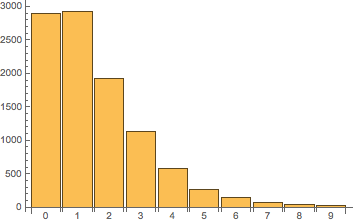
类似地,我们可以算出字母 'f'(数组中的第六个元素)在各个位置出现的分布为 [ 312, 294, 579, 1012, 1781, 2232, 1758, 1129, 586, 317 ],图像如下:
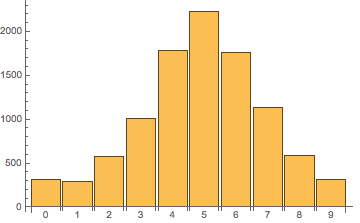
如果排序真的是随机的,那么每个元素在每个位置出现的概率都应该一样,实验结果各个位置的数字应该很接近,而不应像现在这样明显地集中在原来位置附近。因此,我们可以认为,使用形如 arr.sort(() => Math.random() - 0.5) 这样的方法得到的并不是真正的随机排序。
另外,需要注意的是上面的分布仅适用于数组长度不超过 10 的情况,如果数组更长,比如长度为 11,则会是另一种分布。比如:
let a = ['a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j', 'k']; // 长度为11
let n = 10000;
let count = (new Array(a.length)).fill(0);
for (let i = 0; i < n; i ++) {
let arr = [].concat(a);
arr.sort(() => Math.random() - 0.5);
count[arr.indexOf('a')]++;
}
console.log(count);
在 Node.JS 6 中执行,结果为 [ 785, 819, 594, 679, 941, 1067, 932, 697, 624, 986, 1876 ],其中第一个元素 'a' 的分布图如下:
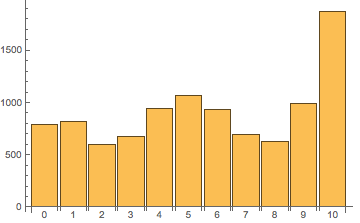
分布不同的原因是 v8 引擎中针对短数组和长数组使用了不同的排序方法(下面会讲)。可以看到,两种算法的结果虽然不同,但都明显不够均匀。
国外有人写了一个 Shuffle 算法可视化的页面,在上面可以更直观地看到使用 arr.sort(() => Math.random() - 0.5) 的确是很不随机的。
探索
看了一下 ECMAScript 中关于 Array.prototype.sort(comparefn) 的标准,其中并没有规定具体的实现算法,但是提到一点:
Calling comparefn(a,b) always returns the same value v when given a specific pair of values a and b as its two arguments.
也就是说,对同一组 a、b的值,comparefn(a, b) 需要总是返回相同的值。而上面的 () => Math.random() - 0.5(即 (a, b) => Math.random() - 0.5)显然不满足这个条件。
翻看 v8 引擎数组部分的源码,注意到它出于对性能的考虑,对短数组(例如长度小于 10)使用的是插入排序,对长数组则使用了快速排序,至此,也就能理解为什么 () => Math.random() - 0.5 并不能真正随机打乱数组排序了。(有一个没明白的地方:源码中说的是对长度小于等于 22 的使用插入排序,大于 22 的使用快排,但实际测试结果显示分界长度是 10。2017-04-14 源码已更新:For short (length <= 10) arrays, insertion sort is used for efficiency.)
解决方案
知道问题所在,解决方案也就比较简单了。
方案一
既然 (a, b) => Math.random() - 0.5 的问题是不能保证针对同一组 a、b 每次返回的值相同,那么我们不妨将数组元素改造一下,比如将每个元素 i 改造为:
let new_i = {
v: i,
r: Math.random()
};
即将它改造为一个对象,原来的值存储在键 v 中,同时给它增加一个键 r,值为一个随机数,然后排序时比较这个随机数:
arr.sort((a, b) => a.r - b.r);
完整代码如下:
function shuffle(arr) {
let new_arr = arr.map(i => ({v: i, r: Math.random()}));
new_arr.sort((a, b) => a.r - b.r);
arr.splice(0, arr.length, ...new_arr.map(i => i.v));
}
let a = ['a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j'];
let n = 10000;
let count = (new Array(a.length)).fill(0);
for (let i = 0; i < n; i ++) {
shuffle(a);
count[a.indexOf('a')]++;
}
console.log(count);
一次执行结果为:[ 1023, 991, 1007, 967, 990, 1032, 968, 1061, 990, 971 ]。多次验证,同时在这儿查看 shuffle(arr) 函数结果的可视化分布,可以看到,这个方法可以认为足够随机了。
方案二(Fisher–Yates shuffle)
需要注意的是,上面的方法虽然满足随机性要求了,但在性能上并不是很好,需要遍历几次数组,还要对数组进行 splice 等操作。
考察 Lodash 库中的 shuffle 算法,注意到它使用的实际上是 Fisher–Yates 洗牌算法,这个算法由 Ronald Fisher 和 Frank Yates 于 1938 年提出,然后在 1964 年由 Richard Durstenfeld 改编为适用于电脑编程的版本。用伪代码描述如下:
-- To shuffle an array a of n elements (indices 0..n-1):
for i from n−1 downto 1 do
j ← random integer such that 0 ≤ j ≤ i
exchange a[j] and a[i]
一个实现如下(ES6):
function shuffle(arr) {
let i = arr.length;
while (i) {
let j = Math.floor(Math.random() * i--);
[arr[j], arr[i]] = [arr[i], arr[j]];
}
}
或者对应的 ES5 版本:
function shuffle(arr) {
var i = arr.length, t, j;
while (i) {
j = Math.floor(Math.random() * i--);
t = arr[i];
arr[i] = arr[j];
arr[j] = t;
}
}
小结
如果要将数组随机排序,千万不要再用 (a, b) => Math.random() - 0.5 这样的方法。目前而言,Fisher–Yates shuffle 算法应该是最好的选择。
评论:
也写一个自己修改的
```Javascript
function shuffle(arr) {
var i;
var randomIndex;
for (i = arr.length; i &amp;gt; 0; i--) {
randomIndex = Math.random() * i;
swap(arr, i, randomIndex);
}
}
// or use functional programing
function shuffle(arr) {
arr.forEach(function (curValue, index) {
var randomIndex = Math.random() * index;
swap(arr, index, randomIndex);
});
}
function swap(arr, indexA, indexB) {
var temp;
temp = arr[indexA];
arr[indexA] = arr[indexB];
arr[indexB] = temp;
}
```
```javascript
function shuffle(arr) {
var i;
var randomIndex;
for (i = arr.length; i &gt; 0; i--) {
randomIndex = Math.floor(Math.random() * i);
swap(arr, i - 1, randomIndex);
}
}
// or use functional programing
function shuffle(arr) {
arr.forEach(function (element, index) {
var randomIndex = Math.floor(Math.random() * (index + 1));
swap(arr, index, randomIndex);
});
}
function swap(arr, indexA, indexB) {
var temp;
temp = arr[indexA];
arr[indexA] = arr[indexB];
arr[indexB] = temp;
}
```
```js
const shuffle = arr => {
arr.forEach((element, index) => {
const randomIndex = Math.floor(Math.random() * (index + 1))
swap(arr, index, randomIndex)
})
}
// 此处用 ES5 的函数写法是为了函数提升
function swap (arr, indexA, indexB) {
[arr[indexA], arr[indexB]] = [arr[indexB], arr[indexA]]
}
```