IE6 下使用 JS 获取路径中包含汉字的 URL 的一个问题
我们经常需要用 JavaScript 获取网页上某个链接的地址(href 属性),很简单,只需要 a.getAttribute("href") 就行了。一切都很顺利,除了万恶的 IE6。
问题
有时候,我们的链接中含有汉字,为了保证链接不会因为编码问题失效,我们先要将汉字转换为 URL 编码的形式。比如,UTF-8 编码的 汉字 将被转为 %E6%B1%89%E5%AD%97,GBK 编码的 汉字 则是 %BA%BA%D7%D6。这样,一个形如:
http://test.com/news/cartoonlist/d14-td12月义乌最有商机的小商品-p1.html
的链接(其中的汉字为 GBK 编码)将被转为:
http://test.com/news/cartoonlist/d14-td12%D4%C2%D2%E5%CE%DA%D7%EE%D3%D0%C9%CC%BB%FA%B5%C4%D0%A1%C9%CC%C6%B7-p1.html
转换之后,在各大浏览器上访问都很正常,用 js 获取链接的 href 值也很正常,除了在 IE6 下。
我们来看一下下面的代码:
<!-- 请在 IE6 下测试本段代码 -->
<a href="http://test.com/news/cartoonlist/d14-td12%D4%C2%D2%E5%CE%DA%D7%EE%D3%D0%C9%CC%BB%FA%B5%C4%D0%A1%C9%CC%C6%B7-p1.html" onmousedown="test(this)" target="_self">链接1</a>
<script>
function test(a) {
alert(a.getAttribute("href"));
}
</script>
点击链接,在除 IE6 的各大浏览器下表现都和预期的一致,如下图:
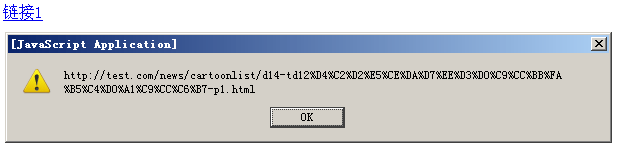
但在 IE6 下,取得的 href 属性中汉字编码的部分变成了乱码:
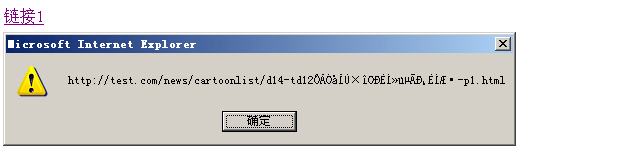
在 IE6 下,如果要对通过 js 获取 href 属性,只要 href 值的 URL 路径中含有汉字等字符(无论这些字符是用 GBK 编码的还是 UTF-8 编码的)的 URL 编码,都将遇到这样的问题。网上搜索了一番,得知大概是由于 IE6 对编码支持的不完善造成的。另外,这个问题只在 URL 编码出现在 URL 路径而不是参数(即 ? 后面的内容)或书签(即 # 后面的内容)中才会发生。比如,下面的代码中,也有 URL 汉字编码,但这些汉字编码都在参数中,所以不会有这个问题。
<!-- 请在 IE6 下测试本段代码 -->
<a href="http://test.com/news/cartoonlist/d14-td.html?subject=12%D4%C2%D2%E5%CE%DA%D7%EE%D3%D0%C9%CC%BB%FA%B5%C4%D0%A1%C9%CC%C6%B7&amp;p=1" onmousedown="test(this)" target="_self">链接1</a>
<script>
function test(a) {
alert(a.getAttribute("href"));
}
</script>
探索
鉴于 IE6 在国内还有巨大的份额,我们必须要设法解决或避免这个问题。避免这个问题的方法很简单,只要规定 URL 路径中不要出现这样的汉字编码即可(URL 参数中可以出现)。但如果 URL 路径中已经大量应用汉字编码了,有办法处理吗?网上搜索了一圈无果,看来只能自己处理了。
经过测试,注意到只有用 js 获取 href 属性的值时会有这个问题,取别的属性(即使是一个自定义属性的值)都正常。比如:
<!-- 请在 IE6 下测试本段代码 -->
<a href="http://test.com/news/cartoonlist/d14-td12%D4%C2%D2%E5%CE%DA%D7%EE%D3%D0%C9%CC%BB%FA%B5%C4%D0%A1%C9%CC%C6%B7-p1.html" my-attr="http://test.com/news/cartoonlist/d14-td12%D4%C2%D2%E5%CE%DA%D7%EE%D3%D0%C9%CC%BB%FA%B5%C4%D0%A1%C9%CC%C6%B7-p1.html" onmousedown="test(this)" target="_self">链接1</a>
<script>
function test(a) {
alert(a.getAttribute("href") + "\n" + a.getAttribute("my-attr"));
}
</script>
可以看到,js 获取的 href 属性中有乱码,但自定义属性的值是正常的。
这就有了第一个解决办法:服务器端生成 HTML 时,给每个超链接再加一个自定义属性,值和 href 的值一样。客户端 js 要处理 href 时,读取这个自定义属性就行了。
但这个方法显然很不靠谱,因为工程太浩大了,而且这个自定义属性对于除 IE6 以外的浏览器来说都是毫无用途的。
继续探索,突然想到,这个链接元素的 outerHTML 属性中的 URL 是否正常呢?试了一下,发现 outerHTML 属性是正常的,没有乱码。于是,就有了下面的更好的解决办法:
解决方案一
<!-- 请在 IE6 下测试本段代码 -->
<a href="http://test.com/news/cartoonlist/d14-td12%D4%C2%D2%E5%CE%DA%D7%EE%D3%D0%C9%CC%BB%FA%B5%C4%D0%A1%C9%CC%C6%B7-p1.html" onmousedown="test(this)" target="_self">链接1</a>
<script>
function test(a) {
alert(a.getAttribute("href")); // IE 6 下有乱码
var href;
if (a.outerHTML &&
(href = a.outerHTML.match(/<a>]*?href=['"]?(.*?)['"s]/i)) &&
(href = href[1]) != a.getAttribute("href")
) a.setAttribute("href", href);
alert(a.getAttribute("href")); // IE 6 下正常
}
<script>
原理很简单,读取链接 a 的 outerHTML,用正则从中找到 href 的值,这个值就是我们期望的没有乱码的值。注意,上面的代码中我们又把提取到的 href 的值写回了 href 属性,这么做的原因是用 js 写 href 属性后,再次用 js 读取时就是刚才写入的值(即刚才提取的没有乱码的值)。
这种方法很简单直观,不过有一个缺点是要读取 outerHTML 的值。另外,@yuyu1911 也总结了另外一种解决办法,我将他的代码稍作整理后,把上面的 test 函数写成如下形式:
解决方案二
function test(a) {
alert(a.getAttribute("href")); // IE 6 下有乱码
var href;
if (a.outerHTML &&
(href = a.outerHTML.match(/<a>]*?href=['"]?(.*?)['"s]/i)) &&
(href = href[1]) != a.getAttribute("href")
) a.setAttribute("href", href);
alert(a.getAttribute("href")); // IE 6 下正常
}
function test(a) {
//alert(a.getAttribute("href")); // IE 6 下有乱码
var href = a.getAttribute("href");
if (isIE6()) {
// IE 6 下,汉字自动转义后变乱码了,采用 escape 方法对其进行编码能恢复其编码,
// 但同时也将 ?:&=# 等字符也进行了编码,所以对这些字符还得进行解码
var i = href.search(/[?#]/);
if (i == -1) i = href.length;
href = escape(href.substr(0, i)).replace( // 将 ?:&=# 字符进行解码
/(%3F|%3A|%26|%3D|%23)/g,
function($0, $1) {
return unescape($1);
}
) + href.substr(i);
}
alert(href);
}
// 判断是否为 IE6
function isIE6() {
// ...
return true;
}
这个方法的特点是不需要额外地读取 outerHTML 属性的值,同时需要处理的正则也简单一些,我简单测试了一下,它在 IE6 下性能比上面要读取 outerHTML 的方法稍高一些。这个方法的不足是需要判断浏览器是否为 IE6,因为在其它浏览器下,上面的处理过程会将正常的 URL 编码再编码一次。另外,上面的 isIE6 函数我故意留空了,因为判断浏览器版本的方法通常在大家常用的框架或库中已经有了,这儿我就不再重复实现了。
这样,在各大主流浏览器中,我们都能顺利地用 js 取得链接的 href 值了,即使 URL 路径中有经过 URL 编码的汉字。
后续更新
上面的内容写好后,经 @wljray 提醒,注意到在 IE 下,node.getAttribute 有一点不同,它可以有两个参数,具体见这儿。具体到这个问题,通过 getAttribute 取链接的 href 属性时,可以传两个参数,如下:
a.getAttribute("href", iFlags);
其中 iFlags 的值可以为 0、1、2、4。测试如下:
<!-- 请在 IE6 下测试本段代码 -->
<a href="/news/d14-td12%D4%C2%D2%E5%CE%DA%D7%EE%D3%D0%C9%CC-p1.html" onmousedown="test(this)" target="_self">链接1</a>
<script>
function test(a) {
var v = [0, 1, 2, 4], s = "", iFlags;
for (iFlags = 0; iFlags &lt; v.length; iFlags ++) {
s += "iFlags = " + iFlags + "\n";
s += "href = '" + a.getAttribute("href", iFlags) + "'\n\n";
}
alert(s);
}
</script>
注意上面的代码中,我们的 href 写的是相对路径。测试结果如下,一图胜千言:
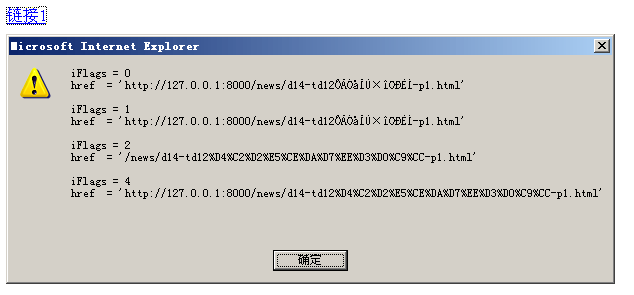
可以看到,iFlags 为 0 或 1 时,就是默认情况,有乱码,返回的是绝对路径;iFlags 为 2 时,没有乱码,返回相对路径;iFlags 为 4 时,没有乱码,返回绝对路径。
另外,getAttribute 的第二个参数在其它浏览器中都会被安全地忽略掉,所以,综合起来,本文开头提出来的问题的最佳解决方案如下。
最终解决方案
function test(a) {
return a.getAttribute("href", 2); // 搞定
}
这样,getAttribute 在各大浏览器(包括 IE6)中就都有一致的表现了。绕了一大圈,尝试了各种方法,没想到最后最佳的解决方案居然是浏览器本来就支持的。但 IE 这个属性太不常用了,我今天还是第一次知道,再次感谢告诉我这个属性的 @wljray。:-)
评论:
不错,解决方案收藏了。
最终解决方案中的 iFlags 应该是取 4 吧?
2 和 4 的区别是,2 取到的是 href 的实际值,如果 href 里填的是绝对路径取到的就是绝对路径,如果填的是相对路径取到的就是相对路径,4 取到的总是补全后的绝对路径。
看你的需求,如果无论 HTML 中 href 填的是什么,你想取到的都是绝对路径,就用 4 。
哦,注意到了,谢谢
我想问一下怎么把utf-8的那一堆编码转化为汉字?
使用 decodeURI 或 decodeURIComponent ?如果情况比较复杂可能需要自己实现。
自己实现可以参考这篇帖子:http://www.wenlingnet.com/index.php/42/。
楼主喜欢讲废话,鉴定完毕……